Attention-guided Temporally Coherent Video Object Matting
Abstract
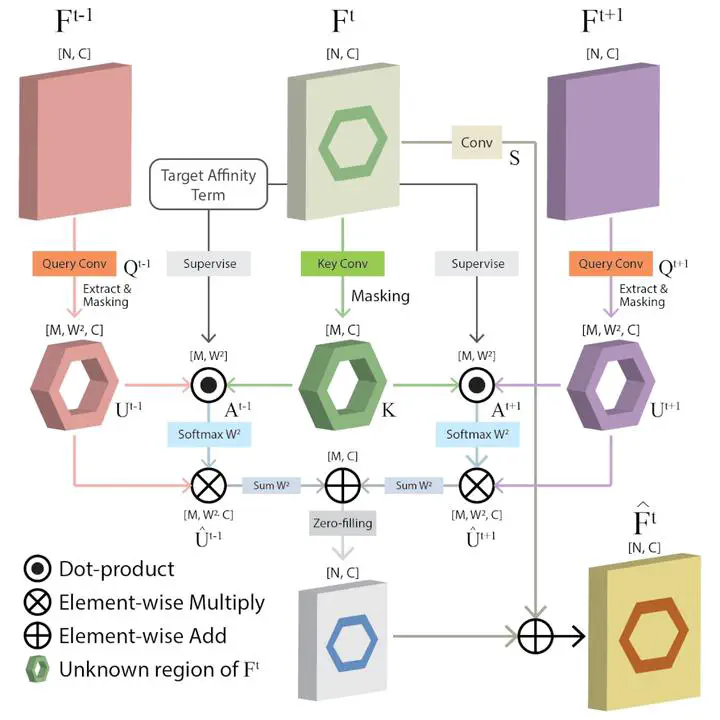
This paper proposes a novel deep learning-based video object matting method that can achieve temporally coherent matting results. Its key component is an attention-based temporal aggregation module that maximizes image matting networks’ strength for video matting networks. This module computes temporal correlations for pixels adjacent to each other along the time axis in feature space, which is robust against motion noises. We also design a novel loss term to train the attention weights, which drastically boosts the video matting performance. Besides, we show how to effectively solve the trimap generation problem by fine-tuning a state-of-the-art video object segmentation network with a sparse set of user-annotated keyframes. To facilitate video matting and trimap generation networks’ training, we construct a large-scale video matting dataset with 80 training and 28 validation foreground video clips with ground-truth alpha mattes. Experimental results show that our method can generate high-quality alpha mattes for various videos featuring appearance change, occlusion, and fast motion. Our code and dataset can be found at here.
Chi Wang 王驰
Distinguished Research Fellow
(ZJU tenure-track positions)
My research interests include AIGC, AIGC, Computer Graphics, 3D Vision, Digital Twin.